wPython에서 pandas pkg를 이용하여 Dataframe 작업을 할 때 열 생성/변경/삭제 작업이 많다.
단순한 열 생성/변경/삭제 작업의 경우 간단하지만, 다수 개의 조건하에 있는 열 변경 작업은 생각이 조금 필요하다.
오늘 원소 값 변경을 위해 삽질을 여러 번 하다가.. 발견한 조건에 따른 원소 값 변경 코드를 정리해본다.
1. Dataframe 생성
original dataframe으로 Name, Gender 열을 가진 간단한 df를 생성했다. 이후에는 새로운 열을 생성하고, 그 열에 대한 원소값을 변경할 것이다.
a = pd.DataFrame({'Name':['Jane','Young','Tester','Tester2'],'Gender':['man','woman','woman','man']})print('***** original dataframe *****')print()print(a)
2. 조건에 따른 Dataframe에 새로운 Column 생성
나는 python의 loc 와 str.contains 함수를 사용할 것이므로, 이것을 먼저 간단하게 알아보고 넘어간다.
x.loc: label(값)을 이용하여 values 그룹에 접근(indexing)하는 것.
아래 예시(Example)과 같이 label(값 = viper)에 따른 값들을 출력해주는 method이다.
str.contains: string에서 아주 유용한 함수로, 인자값에 따른 문자열을 찾아준다.
예를들어, a={"장미꽃", "꽃집", "배꽃나무", "매화는 매실의 꽃", "가나다", "abc", "꽂", "꼽", "꽁", "꼿꼿"} 라는 배열에서 a.str.contains("꽃")을 실행하면 "꽃"을 포함한 모든 단어를 출력할 수 있다.
즉, '기업명' 이라는 열에서 'xx전자'라는 이름을 가진 기업명을 찾아 '업무분야' 라는 카테고리를 새로 만든 후, '전자'라는 값을 삽입한다고 치자. 그럴 경우 기업명엔 '삼성전자', 'LG전자', 'ABC전자'등 많은 값이 있을 지라도 이 분류는 '전자'로 처리될 수 있다.
그러면 이제 나의 예시에서 loc와 contains method를 함께 사용해본다.
a.loc[a['Gender'].str.contains("wo")]) # a['Gender']열에서 "wo"가 포함된 값의 grp을 찾는다.
그 결과값으로 1, 2번 값들이 출력된다.
그러면 이제 해당 값("wo")을 가진 그룹에 'category'라는 column을 추가하여 '여자'라는 값을 생성한다.
딥러닝을 돌리기 위해 텐서플로우(tensorflow)에서 필요한 패키지가 몇 가지 있는데, 그 중 opencsv 및 cv2가 설치되지 않는 문제가 있다.
powershell 에서 pip install opencv, pip install cv2로 해당 패키지를 설치하게 되면 아래와 같은 에러가 발생하여 설치가 실패되는데, 이유는 python 패키지 이름이 아니기 때문에 에러가 발생한다.
이들은 둘 다 pip에서 설치할 수있는 opencv-python 패키지의 일부로 포함되어 있는데, 한번 설치해보자.
pip install cv2 pip install opencv 실행 결과 PSC:\Users\BAEK> pip install cv2 ERROR: Could not find a version that satisfies the requirement cv2(from versions: none)ERROR: No matching distribution found for cv2
개요 파이썬을 활용한 머신러닝의 첫 관문! 구글 Colab(코랩)의 환경구성 및 기본 사용법을 다룬 포스트입니다. 목차 Colab이란 무엇인가? Colab 환경설정 Colab을 활용한 간단한 예제 작성 Colab & Markdown Colab이란 무엇인가? 구글 코랩(Colab)은 클라우드 기반의 무료 Jupyter 노트북 개발 환경이다. 내부적으로는 코랩 + 구글드라이브 + 도커 + 리눅스 + 구글클라우드의 기술스택으로 이루어진...
인공지능1 기말과제로 제출한 개인 프로젝트이다. 기말고사를 열심히 공부하느라(?) 과제에는 많은 힘을 쏟진 못하였다... 그래도 언젠가는 도움이될 것 같아서 제출한 과제 그대로 복붙을 해본다.
요약
Object detection을 주제로 인공지능1 이미지분석 개인프로젝트를 진행하였다. 이미지 분석에는 Classification, Object detection 등이 존재하나 Object detection이 결국 Classification이 포함되며, 더 심화되는 개념으로 Object Detection에 대해 금번 프로젝트로 정리해보았다. 해당 분석을 진행하기 위해 제2장에서 CNN, R-CNN, Fast R-CNN, Faster R-CNN 그리고 SSD(Sigle Shot Multi-box Detector)에 대한 이론을 정리하였으며, 제 3장에서는, Google에서 제공하는 Tensorflow Hub를 통해 Faster R-CNN과 SSD+mobilenet v2 모듈을 다운받아 구현함으로써 해당 방법론들에 대한 결과값과 소요시간을 계산하고 Output 이미지를 확인해보았다.
제 1 장 서론
현재 인공지능은 인간과 기계사이의 능력 격차를 해소하는 획기적인 성장을 기록해오고 있다. 연구원들은 기계(Machine)가 놀라운 성과를 거둘 수 있도록 수많은 필드의 방면을 연구하는데, 그런 많은 분야 중 하나가 Computer Vision이다. 이 분야는 기계가 인간처럼 세상을 보고, 비슷한 방식으로 인지하고, 심지어 이미지&비디오 인식(Image & Video recognition), 이미지분석&분류(Image Analysis & Classification), 미디어 재생산(Media Recreation), 추천시스템(Recommendation Systems), 자연어처리(Natural Language Processing) 같은 다수 작업에 지식을 사용할 수 있도록 한다. 딥러닝(Deep Learning)과 함께하는 Computer Vision의 발전은 주로 특정한 알고리즘인 CNN을 통해 구성되며 시간에 따라 완벽해지고 있다.
금번 과제의 구성은 제2장에서 CNN의 발전과정(CNN, R-CNN, Fast R-CNN, Faster R-CNN)에 대해 이론적으로 알아본 뒤, 제 3장에서 R-CNN 코드 구현을 통해 이미지를 예측 및 결과에 대해 기술하였다. 제4장 결론에서는 금번 프로젝트 내용을 정리하고 한계점에 대해 기술하였다.
제 2 장 CNN의 발전과정 및 SSD
2.1. CNN (Convolutional Neural Networks)
CNN(Convolutional Neural Network)은 딥러닝 알고리즘(Deep Learning Algorithm)으로, 이미지를 입력하여 이미지 내 다양한 측면/객체의 가중치(learnable weights, biases)를 할당하여 각각을 서로 다른 것으로 구별할 수 있게 할 수 있다. 전처리과정은 다른 분류 알고리즘과 비교했을 때 훨씬 적어 계산에 편리하며, 이전 방법에서 필터는 직접 손으로 동작하도록(hand-engineered) 설계되어 충분한 training을 진행해야 했지만, CNN은 이러한 필터/특성을 스스로 학습할 수 있는 능력을 가지고 있다. CNN의 구조는 인간 뇌에 있는 뉴런의 연결 패턴과 유사하며, 개별 뉴런은 Receptive Field로 알려져 있는 visual field의 제한된 영역에서만 자극에 반응한다. 인공지능1 수업에서 배웠듯, 해당 필드의 집합이 이미지 전체를 다루기 위해 아래 ‘[그림-1] CNN sequence to classify handwritten digits’ 과 같이 손으로 쓴 숫자를 CNN에서 분류하기위해CONV, RELU, POOL, FC layer가 사용되며, Convolution layer에서는 tensor를 입력 받아 영역별로 weights를 곱해 각 뉴런의 아웃풋을 계산한다. 여기서 filter라는 개념이 추가되는데, filter가 많아질수록 결과 값이 복잡해지기 때문에, 이후 Pooling layer를 통해 이미지를 downsizing 하여 계산결과가 작아지게 된다. 최종적으로는 FC(Fully Connected) Layer를 사용하여 class의 점수를 계산하게 된다. 각 layer내에서는 계산을 위해 Padding, Filter, Stride등 여러 Hyperparameters가 사용된다.
그림 1. A CNN sequence to classify handwritten digits
2.2. R-CNN (Regions with Convolutional Neural Networks)
RCNN은 CNN을 본격 이용하여 딥러닝 기반 이미지 분류기를 feature extractor로 사용하여 object detection, segmentation에서 높은 보였다는 점에서 주목을 끌었다. 최초의 R-CNN 논문에서의 문제 정의는 1) Localizing objects with DNN, 2) Training a high-capacity model with small quantity of annotated detection data로 완전히 새로운 방식이 아닌, Neural Network 기반의 detection feature extractor를 만들어내려고 시도했던 것으로 판단한다. R-CNN은 크게 아래 4가지 방법으로 나뉜다.
그림 2. R-CNN 학습 구조
1) Input image: 이미지를 입력한다.
2) Region proposal algorithm
대상의 class를 구분하지 않고 이미지로부터 region을 추출해낸다. 알고리즘은 상관없으며 비슷한 질감이나 색, 강도를 가진 인접한 픽셀들을 연결하여 bounding box를 구성하는 Selective search 방법 등을 이용한다. 이 방법으로 생성된 bounding box의 output을 다시 CNN 레이어의 input으로 활용하고, input으로 변환하는 과정에서 압축(warp)을 한다.
3) CNN: Feature vector extract
앞 단계에서 생성한 region을 압축한 input으로, 미리 training된 CNN 모듈에 통과시켜 새로운 Feature를 생성한다. AlexNet, VGGNet을 기반으로 튜닝 과정을 거친 CNN 모델을 사용한다. 기존의 CNN Classifier에서 최종 softmax 분류기 부분을 제외한 output을 결과물 feature로 사용하는데, 예를 들면 Kaggle이나 다른 분석 대회용 dataset을 보면 불분명한 image feature들이 존재하는 경우가 있는데, 이 feature를 나타낸 다는 것이 그 예이고, 이 결과물을 fixed-length feature vector라고 부른다.
4) Classify Algorithm
마지막으로 Fixed-length feature vector를 input으로 하는 분류기를 추가한다. Region proposal 단계에서 생성된 object를 CNN 레이어에 통과시켜 fixed-length feature vector로 변환한다. 그리고 이 input값을 바탕으로 객체여부를 분류한다. 이 단계를 나눈 이유는, 도메인 목적에 맞는 분류기를 설정 및 유효한 영역 판별을 판단하기 위함이다.
2.3. Fast R-CNN
Fast R-CNN은 R-CNN으로부터 속도를 개선시키기 위해 Rol pooling을 중간 과정에 삽입, 연산을 급격하게 줄여 속도를 개선시킨 모델이다. 기존 R-CNN은 RP(Region Proposal)마다 CNN을 적용했기 때문에 Selective search * CNN의 연산을 수행했지만, Fast R-CNN은 (Selective search +Rol Pooling) *1의 연산으로 급격하게 연산이 줄었다.
그림 3. Fast-CNN 구조
2.4. Faster R-CNN
Fast R-CNN을 통해 많은 시간과 비용이 절약되었지만, RP(Region Proposal) 생성 자체에 많은 시간이 소요되었다. Fast R-CNN에서는 selective search를 수행하는 region proposal이 외부에 존재하여 inference에서 병목(Bottleneck)을 일으켰기 때문에, Faster R-CNN에서는 RPN(Region Proposal Network) 자체를 학습함으로써 selective search 없이 RPN을 학습하는 구조로 모델이 만들어졌다. RPN은 Feature map을 input으로, RP를 output으로 하는 네트워크이며, selective search의 역할을 온전히 대체한다. 또한, Fast R-CNN의 경우 Selective search가 주는 bounding box 좌표를 이용하여 학습했지만, Faster R-CNN은 미리 정의한 reference bounding box인 anchor라는 개념을 도입하여 다양한 크기와 비율로 n개의 anchor를 미리 정의하여 sliding window시 sliding 마다 n개의 bounding box 후보를 생성하여 이미지를 학습하게 된다.
그림 4. Faster R-CNN RPN
2.5. SSD(Single Shot Multi-Box Detector)
Faster R-CNN이 등장한 후 더 빠르고 강력한 Detector인 SSD가 등장했다. Faster R-CNN은 기존 R-CNN의 속도와 비용을 개선했지만 7FPS with mAP 73.2% 의 느린 속도에 실시간 영상분석에 사용할 수 없었다. YOLO는 속도는 빨랐으나 45FPS with mAP 63.4%로 성능을 포기해야 했다. 하지만 SSD는 기존 R-CNN에서 사용했던 RP 추출 및 Resampling 과정을 제거하여 59FPS with mAP 74.3%으로 높은 정확성과 빠른 속도를 모두 얻어냈다. SSD는 말 그대로 사진의 변형 없이 그 한장으로 훈련, 검출을 하는 Detector이다. 기존 CNN에서는 이미지에서 객체 유무를 판단하기 위해 그림을 자르거나 변형해야 하여 오랜 시간이 소요되었지만, SSD는 기존 구조 뒤 보조 구조를 붙여 얻은 Multi-scale feature maps을 이용하여 이 문제를 해결하였다. 아래 사진에서 개의 크기는 사진의 1/3이지만, 고양이는 1/6정도로 둘 간 크기 차이가 크다. 이를 한 가지 feature map에서 구하려면 bounding box의 크기 차이로 인해 box의 크기 추정, 위치추정까지 많은 과정이 필요하다. SSD는 feature map을 여러 개의 크기로 만들어서 큰 map에서는 작은 물체의 검출을, 작은 map에서는 큰 물체의 검출을 하도록 만들어 이 방식은 resampling을 없애면서도 정확도 높은 결과를 도출하게 되었다.
그림 5. SSD feature map
제 3 장 Faster R-CNN & SSD+mobilenetV2 Object Detection 실습
Faster R-CNN패키지와 SSD+mobilenetV2 Object Detection 패키지를 활용하여 Object Detection을 진행하였다. 페이지 용량 문제로 코드는 주석처리를 포함하여 GitHub에 업로드 하였으며, 해당 페이지에서는 Input image에 따른 각 Detection별 Output만 기술한다.
2.1. Input Image 및 Object detection 결과
Input 이미지는 우리학교 NEW H 에서 찍은 사진으로 faster R-CNN과 SSD를 적용하였다.
좌측 결과가 faster R-CNN 적용, 우측 결과가 SSD 적용 결과이다. 이론대로 SSD가 더 빠른 Detection time(Inference time)을 가지고 더 많은 object를 탐지함을 알 수 있었다.
* 코드는 다른 포스팅으로 이어서 업로드하겠다.
제 4 장 결론 및 한계점
인공지능1 수업에서 간략히 다룬 R-CNN에 대해 이론적으로 더 알아보고, 실제 코드 적용을 통해 Object Detection을 확인하였다는 데에 의의가 있다. 하지만 R-CNN, Fast R-CNN, Faster R-CNN에 대해 Google의 TensorFlow Hub에서 Faster R-CNN을 제외한 패키지를 찾지 못하여 직접 Inference Time과 Accuracy 측정값을 비교해보지 못하였다. 아쉬움을 극복하기 위해 Object detection 분야에서 small하고 fast한 장점을 가진 SSD-based object detection model을 함께 학습해보았고, 실제로 SSD 모듈이 Faster R-CNN보다 2배이상 빠르고 많은 예측을 가짐을 확인할 수 있었다. 해당 코드와 결과는 Github에 주석을 포함하여 업로드 하였다.
참고 문헌
Sumit Saha(2018), A Comprehensive Guide to Convolutional Neural Networks — the ELI5 way
Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik(2014), Rich feature hierarchies for accurate object detection and semantic segmentation Tech report (v5)
Shaoquing Ren, Kaiming He, Ross Girshick, and Jian Sun(2016), Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Matthijs hollemans(2018), MobileNetV2 + SSDLite with Core ML
Wei Liu 외(2016), SSD: Single Shot MultiBox Detector
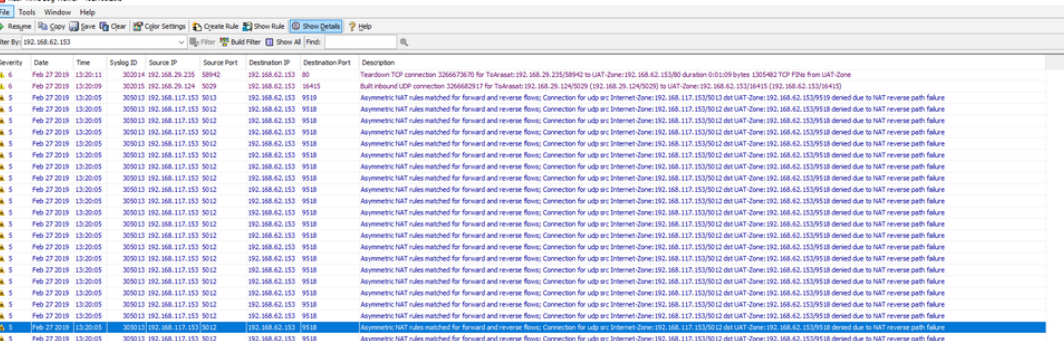
* 망 구성 10.100.30.101 -- VPN 1 -- ( Public ) -- VPN 2 (10.251.212.240) -- 10.90.65.182
10.100.30.101 -> 10.90.65.182로 pkt을 전송할 경우, VPN2 <-> 10.90.65.182 사이 망이 굉장히 복잡하여 10.100.30.101 - 10.90.65.182에 대한 라우팅을 설정할 수 없는 구간이다.
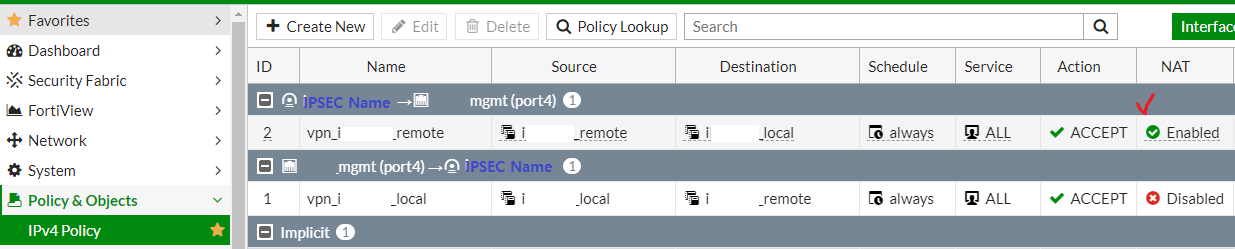
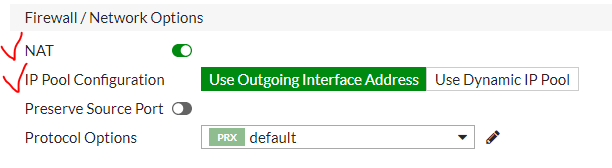
이에따라 아래와 같이 NAT를 설정했다. NAT를 설정한 구간은, 10.100.30.101 --> 10.90.65.182 이며 'Use Outgoing Interface Address'를 설정했다.
* 설정방법 . Policy & Objects > IPv4 Policy > 구간선택
* packet 확인 아래와 같이 10.100.30.101 -> 10.90.65.182 pkt이 인입될 경우 10.100.30.101은 10.251.212.240으로 Translation 되어 통신이 완료된다.
FortiVPN # dia sniffer packet any 'host 10.90.65.182' 4 interfaces=[any] filters=[host 10.90.65.182] 1.026395 iTest_server in 10.100.30.101.36277 -> 10.90.65.182.21: syn 2654734121 1.026511 port4 out 10.251.212.240.36277 -> 10.90.65.182.21: syn 2654734121 4.032451 iTest_server in 10.100.30.101.36277 -> 10.90.65.182.21: syn 2654734121 4.032509 port4 out 10.251.212.240.36277 -> 10.90.65.182.21: syn 2654734121 4.989417 iTest_server in 10.100.30.101.40113 -> 10.90.65.182.21: syn 3357824665 4.989526 port4 out 10.251.212.240.40113 -> 10.90.65.182.21: syn 3357824665 7.990786 iTest_server in 10.100.30.101.40113 -> 10.90.65.182.21: syn 3357824665 7.990834 port4 out 10.251.212.240.40113 -> 10.90.65.182.21: syn 3357824665
* VPN에서 Local Network로 Ping 되더라도, VPN Interface - Local Network간 대역이 다를 경우 Local Network에 대한 Routing을 추가해놓아야 한다. 왜? VPN - Local Network간에는 대역이 동일 or 라우팅 설정 등으로 ping이 이미 되는 상황일 수 있으나, Site-to-Site는 Remote Network 대역을 Source IP로, 우리 Local Network 대역에 붙어야 하기 때문. 따라서, Local Network <-- VPN <-- Remote Network로 pkt이 올 경우 정확한 가이드를 위해 VPN에서도 Local Network에 대해 라우팅 추가를 미리 설정해준다.
* 문제 현상 VPN에 Local Network와 ping이 되지만, 대역이 다른 경우에, 그리고 라우팅이 설정 안 되어 있을 경우, 아래와 같이 수신된 packet을 out 시킬 수 없다. FortiVPN# dia sniffer packet nay 'host 10.100.30.101' 4 intefaces=[any] filters=[host 10.100.30.101] 1.140135 iTest_server in 10.100.30.101 -> 10.90.65.182: icmp: echo request 6.142442 iTest_server in 10.100.30.101 -> 10.90.65.182: icmp: echo request 11.134851 iTest_server in 10.100.30.101 -> 10.90.65.182: icmp: echo request 21.124414 iTest_server in 10.100.30.101 -> 10.90.65.182: icmp: echo request
* 보완 Local Network에 대한 Routing을 설정 후, 아래와 같이 packet은 정상 out된다. FortiVPN # dia sniffer packet any 'host 10.100.30.101' 4 interfaces=[any] filters=[host 10.100.30.101] 73.304160 iTest_server in 10.100.30.101 -> 10.90.65.182: icmp: echo request 73.305211 iTest_server out 10.90.65.182 -> 10.100.30.101: icmp: echo reply 74.309417 iTest_server in 10.100.30.101 -> 10.90.65.182: icmp: echo request 74.312548 iTest_server out 10.90.65.182 -> 10.100.30.101: icmp: echo reply 249.096258 iTest_server out 10.90.65.182 -> 10.100.30.101: icmp: echo reply 250.098714 iTest_server out 10.90.65.182 -> 10.100.30.101: icmp: echo reply ^C 6 packets received by filter 0 packets dropped by kernel
문제가 발생했을 때 분석을 위해 알아본 Cisco ASA VPN의 packet 캡처 방법.
ASDM의 Monitoring에서 실시간 logging을 제공하나, ACL/NAT단에서 걸릴 경우 아무런 패킷도 Trace 창에 보이지 않게되는데, 이럴 때 유용한 패킷 캡처 방법이다.
1. packet capture 방법(설명)
- 출처: Cisco사 CLI 설명서 1: Cisco ASA Series 일반 운영 CLI 구성 가이드, 9.10 : 1223 page ~ 1228 page
옵션 값이 매우 많아서 자료를 그대로 들고왔다.
이렇게 패킷캡처를 설정한 후에는 아래와 같이 패킷 캡처를 보는 명령어가 별도로 존재한다.
패킷 캡처 설정 후, 아래 명령어를 실행해야 실제 캡처되는 패킷을 확인할 수 있다.
2. 설정 및 실습 - CLI
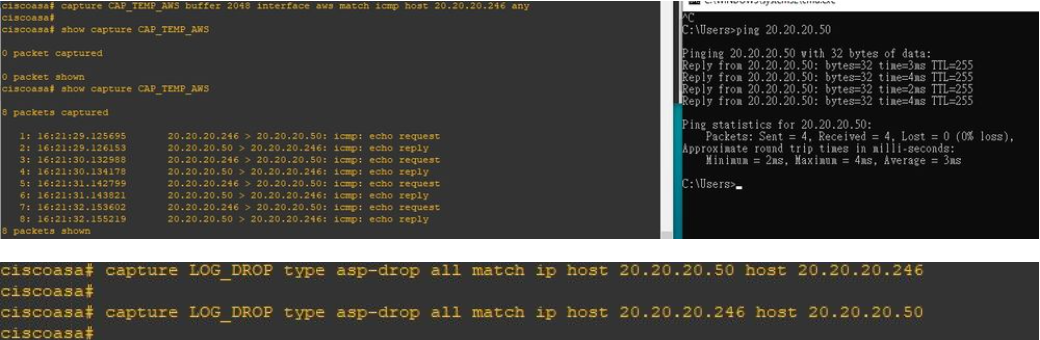
그렇게 직접 실습해 본 packet capture.
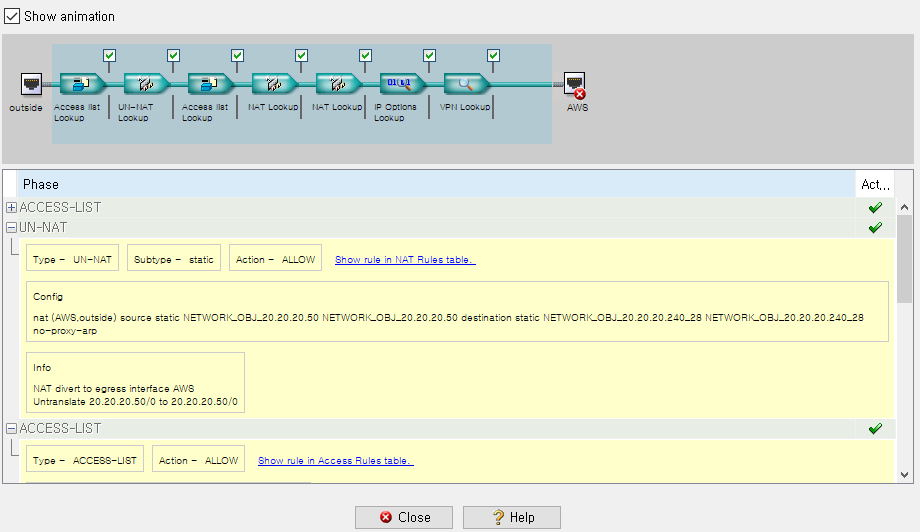
현재 20.20.20.50 - 20.20.20.246은 NAT 설정 오류로 인해 20.20.20.246 -> 20.20.20.50으로 Ping을 실행할 경우 packet이 drop되는 상태이다. 그래서 20.20.20.50 -> 20.20.20.246 방향과 20.20.20.246 -> 20.20.20.50 패킷 캡처를 진행해보았다.
1) packet capture
ciscoasa# capture CAP_TEMP_AWS buffer 2048 interface AWS match icmp host 20.20.20.246 any ciscoasa# capture LOG_DROP type asp-drop all match ip host 20.20.20.50 host 20.20.20.246 ciscoasa# capture LOG_DROP type asp-drop all match ip host 20.20.20.246 host 20.20.20.50
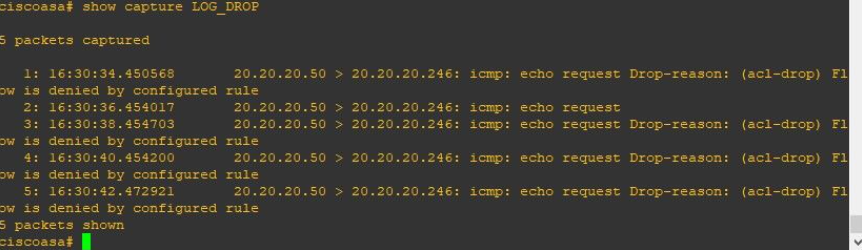
2) show capture
packet 캡처를 설정 후, show capture를 통해 패킷 캡처를 확인한다.
#show capture // 전체 capture되고 있는 packet capture 확인
Result of the command: "show capture" capture CAP_TEMP_AWS type raw-data buffer 2048 interface AWS [Capturing - 456 bytes] match ip host 20.20.20.246 any match ip host 20.20.20.248 any capture LOG_DROP type asp-drop all [Buffer Full - 524284 bytes] match ip host 20.20.20.50 host 20.20.20.248
2-1) 전체 packet capture 확인
#show capture // 전체 capture되고 있는 packet capture 확인 Result of the command: "show capture" capture
CAP_TEMP_AWS type raw-data buffer 2048 interface AWS [Capturing - 456 bytes] match ip host 20.20.20.246 any match ip host 20.20.20.248 any capture LOG_DROP type asp-drop all [Buffer Full - 524284 bytes] match ip host 20.20.20.50 host 20.20.20.248
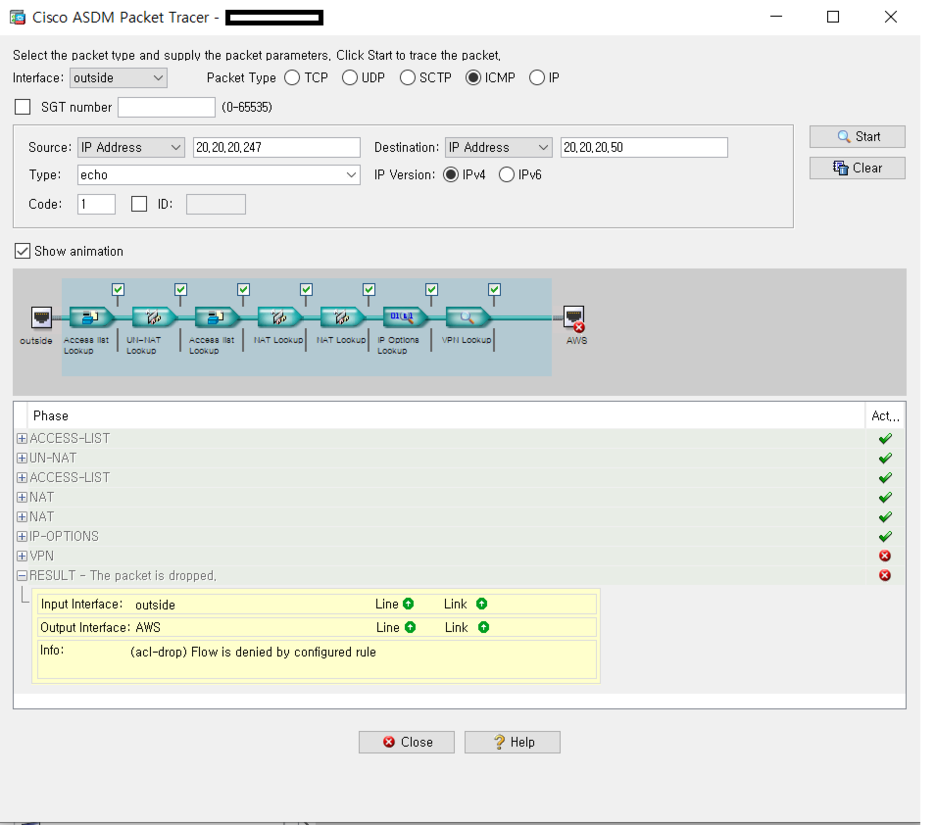
2-2) 특정 packet capture 확인
Remove the captures when done.
ciscoasa# no capture CAP_TEMP_AWS ciscoasa# no capture LOG_DROP