강의가 거의 끝나고, Troubleshooting 섹션이 시작됐다.
크게 아래와 같이 4개의 Failure를 다루는데 하나씩 정리해보겠다.
- Application Failure
- Worker Node Failure
- Control Plain Failure
- Networking
1. Application Failure

먼저, 문제가 발생했을 경우엔 오른쪽과 같이 architecture를 알아야 한다.
어떤 pod와 어떤 service로 구성되어 있는지 말이다.
그래서 FrontEnd부터 (그림에서는 WEB-Service) 천천히 내려가보는 것이다.
그래서 왼쪽과 같이 curl http://web-service.ip:node-port를 를 통해 해당 service가 문제없는지 확인해볼 수 있고,
이후엔 describe를 통해 web-service의 상태 및 config값을 조회할 수 있다.
여기서는 web pod와 연결되기 위해 Selector가 초록으로 마킹되어 있는데, 이게 pod와 맞는지 확인하는 것도 잊지 말아야한다.
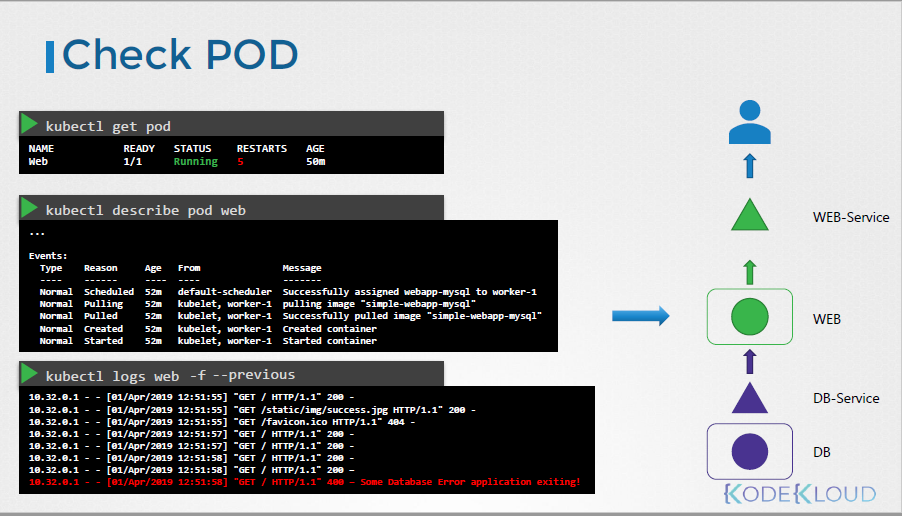
서비스에 이상이 없다면, 이제 pod로 넘어간다.
kubectl get pod를 통해 pod상태를 조회하고, describe로 상세 상태를 보고, logs를 통해서도 문제를 확인할 수 있다.
여기서 -f, --previous 옵션을 붙이면 이전 pod의 상태에 대해서도 확인할 수 있다.
#kubectl logs [pod] -f --previous
여기서도 문제가 없다면, 이제 DB-Service / DB로 내려간다.
이론 설명 후 Practice 강의가 있었는데 대부분은 Selector, DB ID/PW(Root pw까지도), NodePort, Target Endpoint port error(Target Port), ep(endpoint) 문제이다.
ep는 여기서 처음 들어봤는데 # kubectl get po -n [namespace] ep를 통해 조회할 수 있고,
service가 selector를 통해 쳐다보고 있는 Endpoint(pod)를 보여준다.
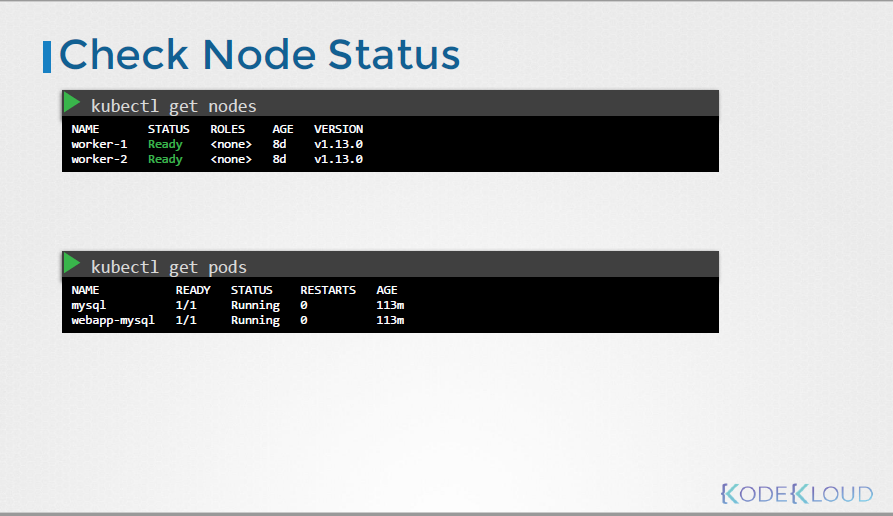
2. Control Plain Failure
1) Node, pods상태, kube-system에 속한 controlplain pods상태를 확인한다.
# kubectl get nodes
# kubectl get pods
# kubectl get pods -n kube-system


만약 Controlplain 컴포넌트들이 service 형태라면, service를 위와 같이 조회할 수 있다.
# service kube-apiserver status
# service kube-controller-manager status
# service kube-scheduler status

service logs를 통해서도 문제를 확인 가능하다.
kube-apiserver의 경우 journalctl를 사용한다.
# kubectl log kube-apiserver-master -n kube-system
# sudo journalctl -u kube-apiserver
Practice test에서는 아래와 같은 내용을 다룬다.
1) pod 한 개가 pending 상태. 근데 pod엔 문제가 없어보임.
-> scheduler issue일 수 있음.
# kubectl get po -n kube-system
// 를 통해 scheduler가 Crashloopbackoff 상태인 것을 확인.
그래서, scheduler를 describe하여 조회한 결과, 'failed to start container "kube-scheduler": Error response from daemon: OCI runtime create failed: container_linux.go:345: starting containre process caused "Exec: \"kube-schedulerrrr\": executable file not found in $PATH: unknown" error가 존재하였음.
=> kube-scheduler-master yaml파일에 가서 수정한다.
# cat /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
// kubectl config.yaml 경로 조회 가능 (/var/lib/kubelet/config.yaml)
# grep -i staticPodPath /var/lib/kubelet/config.yaml
: staticPodPath: /etc/kubernetes/manifest // default path
# cd /etc/kubernets/manifests/
# vi kube/scheduler.yaml
여기서 spec: containers:의 command에 'kube-schedulerrrr'가 있다. 이걸 정상 값(kube-scheduler)으로 수정해준다.
2) deployment를 통해 pod를 2개로 scale
# kubectl scale deployment app --replicas=2 // 그런데 scale이 되지 않음! 그래서 tshoot 진행.
# kubelet get pods -n kube-system // replica를 담당하는 kubec-controller-manager이 역시나 Crashloopbackoff 상태.
# kubectl -n kube-system describe kube-controller-manager 조회 // 문제 없음
# kubectl -n kube-system logs kube-controller-manager-master
// 'stat /etc/kubernetes/controller-manager-xxxx.conf: no such file or directory' 출력
# cd /etc/kubernetes 가보니 controller-manager 파일이 있음. (-xxxx.conf 가 아님)
# vi /etc/kubernetes/manifests/kube-controller-manager.yaml 파일 조회
// spec: containers: command에 있는 kueconfig=/etc/kuberenets/controller-manager-xxxx.conf 파일 수정
이후 deployment 및 controller가 정상 동작되고 replica도 정상 동작하는 것을 확인했다.
3) controller-manager의 re-broken
# kubectl get pods -n kube-system // kube-controller-manager-matser = Crashloopbackoff
# kubectl describe po kube-controller-manager-master -n kube-system // 이슈 없어보임
# kubectl logs kube-controller-manager-matser -n kube-sysetm
// 'unable to load client CA file: unable to load client CA file: open /etc/kuberenetes/pki/ca.crt: no such file or directory' 라는 에러 존재
# vi /etc/kubernetes/manifest/kube-controller-manager.yaml 확인
// ca.crt를 쓰고 있는 부분 확인. mountpath가 /etc/kubernetes/pki를 가지고 있는 것의 name이 'k8s-certs'임.
이걸로 다시 파일 내 조회. 그리고 그것들의 path 확인. WRONG-PKI-DIRECTORY가 있음.
# cd /etc/kubernetes/WRONG-PKI-DIRECTORY/
// 직접 해당 디렉토리 내 ca.crt가 있는지 확인. 그런데 파일이 없음.
# cd /etc/kubernetes/pki/
// 여기에 key값들 있는 걸 확인
# vi /etc/kubernetes/manifest/kube-controller-manager.yaml 확인
// k8s-cert를 쓰고 있는 path를 확인. hostPath가 /etc/kubernetes/WRONG-PKI-DIRECTORY로 설정되어 있음.
이걸 /etc/kubernetes/pki로 변경
3. Worker Node Failure
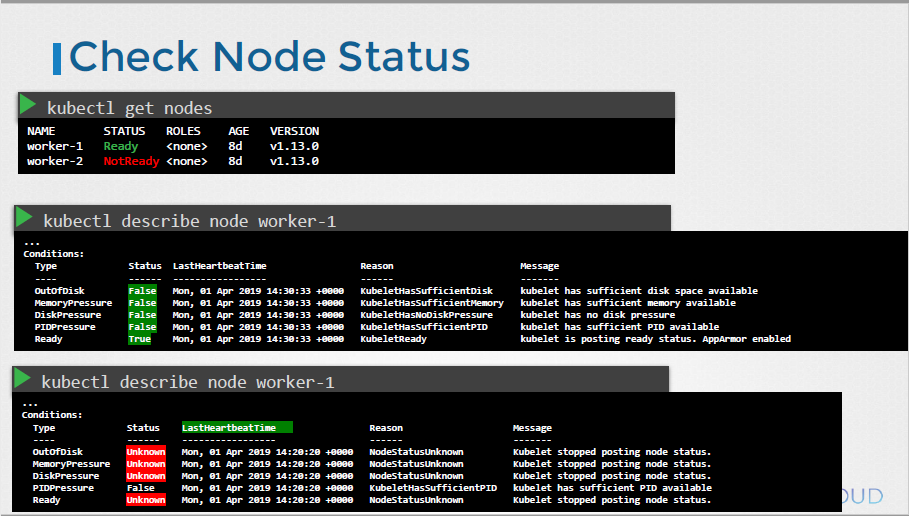
Worker node가 문제있을 땐 node 상태 및 kubelet, Certificates (만료 여부 등)를 확인해볼 필요가 있다.
- Practice에서는 kubelet과 kube-proxy에 대해 다룬다.
1. node 01 Not ready with kubelet
1) kubelet get nodes를 조회했더니, node01이 Not Ready 상태이다.
2) ssh node01로 들어간다.
3) ps -ef | grep kubelet // kubelet이 running중이 아니었다.
4) systemctl status kubelet.service // inactive 확인
5) systemctl restart kubelet // active가 되었다.
6) kubelet get nodes // node01이 ready 상태로 변했다.
2. Node 01 Not Ready with kubelet
1) kubelet get node // node01 = not ready
2) kubectl describe node node01 // 별다른 게 없다.
3) ssh node01
4) sytsemctl status kubelet.service -l // activating 상태
5) journalctl -u kubelet // kube-proxy log 조회
'open /etc/kubernetes/pki/WRONG-CA-FILE.crt: no such file or directory 확인
6) cd /etc/systemd/system/kubelet.service.d/ // kubelet config 조회. 10-kubeadm.conf가 존재
7) cat 10-kubeadm.conf // Environment=KUBELET_CONFIG_ARGS 및 KUBELET_KUBECONFIG_ARGS 존재
// KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml 조회
8) vi /var/lib/kubelet/config.yaml
9) /pki/WRONG-CA-FILE.crt 존재, 이부분 수정
10) cd /etc/kubernetes/
11) ls 조회 시 pki/ 및 kubelet.conf뿐.
pki/에 들어가보니 ca.crt가 있음. 즉, 경로는 /etc/kubernetes/pki/ca.crt가 되어야 함.
12) vi /var/lib/kubelet/config.yaml에서 /etc/kubernetes/pki/WRONG-CA-FILE.crt -> /etc/kubernetes/pki/ca.crt로 변경
13) systemctl daemon-reload
14) systemctl restart kubelet
15) kubelet은 active상태가 되었고 node는 ready 상태가 되었다.
3. Node01 Not Ready with kubelet
1) kubelet describe node node01 // 도움되는 정보 없음
2) ssh node01
3) sytsemctl status kubelet // active & running, but error exist
'dial tcp 172.17.0.22:6553: connect: conenction refused'
4) journalctl -u kubelet // kube-proxy log 조회, 동일한 err 존재
5) kubelet cluster-info // master node에서 master ip 및 port 확인 (172.17.0.22:6443)
6) ssh node01
7) cd /etc/systemd/system/kubelet.service.d/ // kubelet config 조회. 10-kubeadm.conf가 존재
8) cat 10-kubeadm.conf // kubeconfig=/etc/kubernetes/kubelet.conf 확인
9) vi /etc/kubernetes/kubelet.conf // server section에서 port 변경 ( 6553-> 6443)
10) system daemon-reload
11) system restart kubelet
12) kubelet은 active 및 error가 존재하지 않으며 node또한 ready 상태가 됨.
출처: Udemy 사이트의 Certified Kubernetes Administrator (CKA) with Practice Tests 강의
'직장생활 > Kubernetes(K8s), Docker' 카테고리의 다른 글
| K8s Statefulset tag값 수정 에러(원복) 해결 (ft. Prometheus 설치) (0) | 2022.04.20 |
|---|---|
| Docker Image 불러오기 (docker pull/save/load/push) (0) | 2022.04.20 |
| K8s - LVM 설정 적용 (0) | 2021.10.27 |
| Certified Kubernetes Administrator (CKA) - 9 Ingress (ft. Udemy) (0) | 2021.10.25 |
| Certified Kubernetes Administrator (CKA) - 8 Storage (ft. Udemy) (0) | 2021.10.18 |