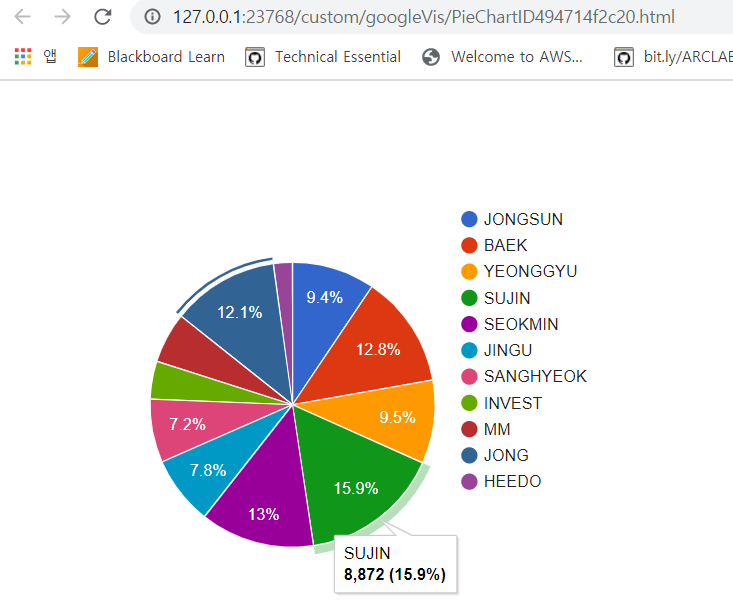
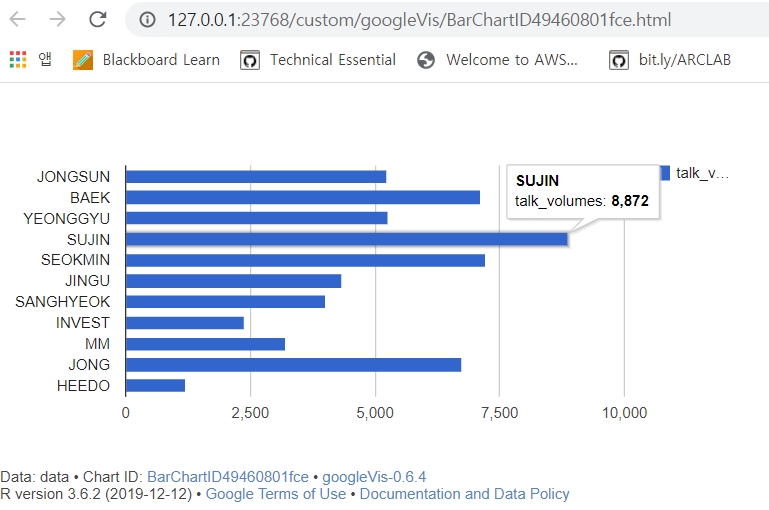
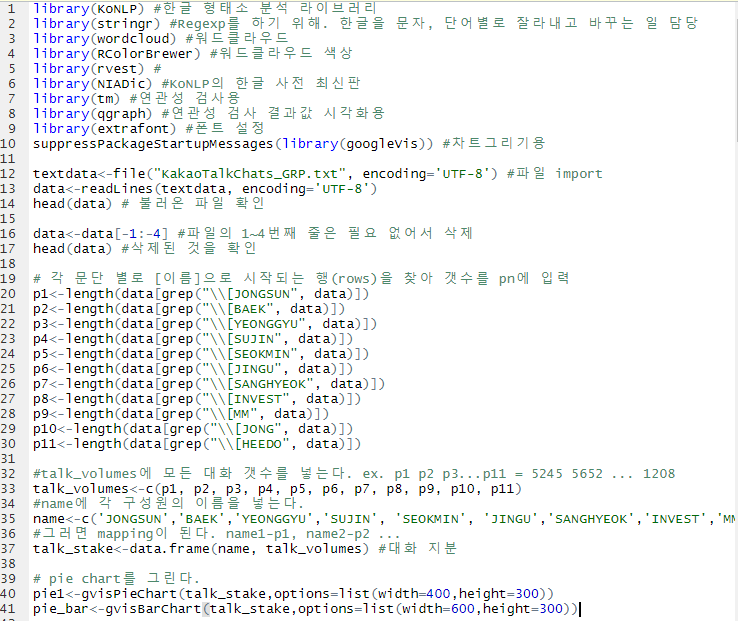
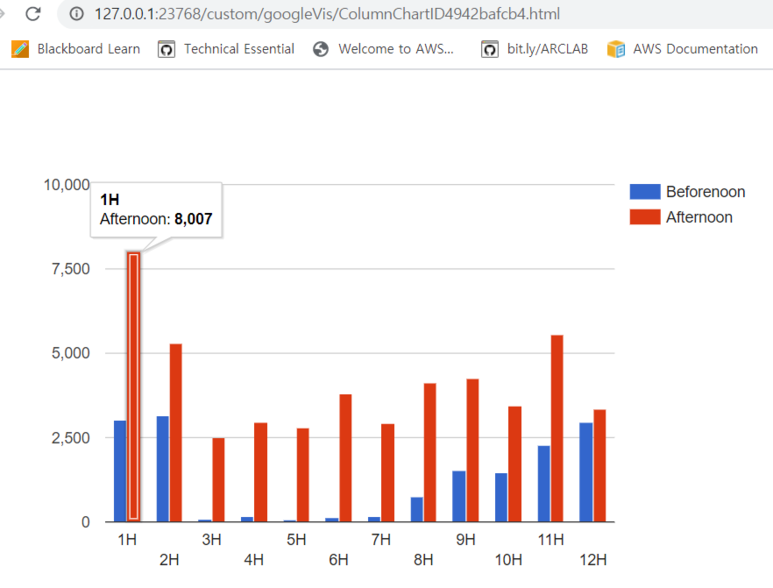
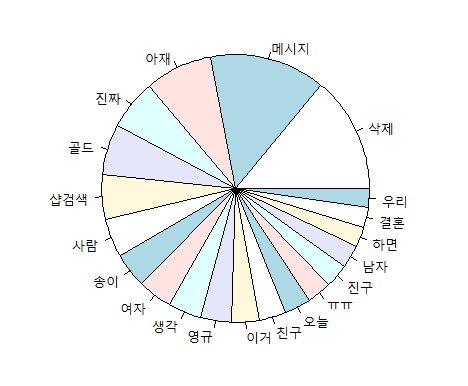
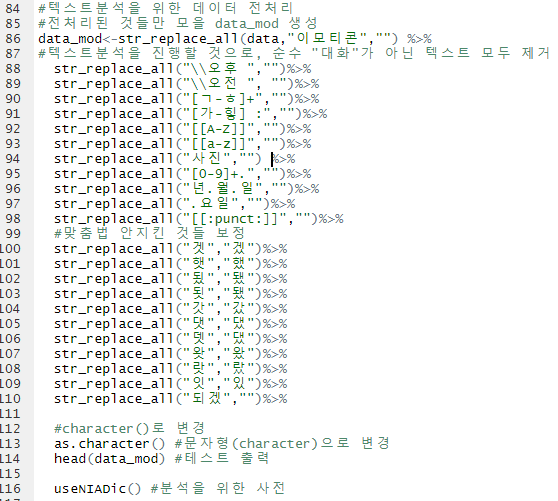
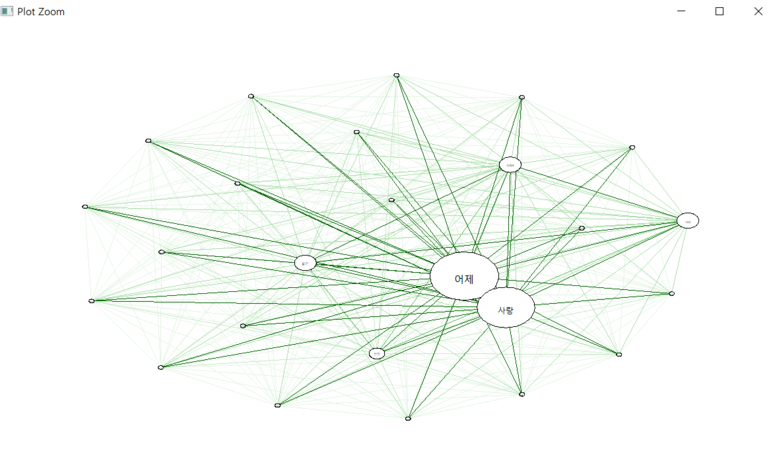
.하고싶은 분석이 있어서 R에서 Konlpy 를 다운받으려고 시도했다: 2020-02-07
> install.packages("KoNLP")
WARNING: Rtools is required to build R packages but is not currently installed. Please download and install the appropriate version of Rtools before proceeding:
#x축(country) 회전 # 상위 5개 국가 출력 ==> 상위5국가: 리투아니아, 스리랑카, 러시아, 헝가리, 벨라루스 // 한국: 11위 data[['country','suicides/100k pop']].groupby('country', as_index=False).mean().sort_values(by='suicides/100k pop', ascending=False).head()
결론적으로 전세계 자살률은 남성일수록, 고령일수록, gdp와는 관계가 없고, 전쟁과 가까운 세대일수록 높았다.
개인적인 생각으로는 못사는 나라일수록 자살률이 높다기보다는, 본인이 처한 경험과 환경에 따라 다른 것이 아닐까 생각이 든다. 후진국의 사람들은 다른 나라를 경험해보았을까? TV조차 없을텐데 그들에게 비교대상은 그 주위사람들뿐이지 않을까. 특히 나이가 먹을수록 몸도 마음도 약해지고, 주도적으로 할 수 있는 것 조차 한계가 생기기 때문에 안좋은 생각을 하기 상대적으로 쉬울 것 같다. 여기까진 내 생각일 뿐이고 또 다른 재미있는 주제가 있으면 들고오겠다 : )
3-1학기는 시험보랴 프로젝트하랴 정말 바빴었고 힘들었는데 지금보니 느낌이 또 색다르다! 역시 지나고보면 다 추억인가보다 !!(???)ㅋㅋㅋㅋㅋ
TensorFlow는 머신러닝을 위한 엔드 투 엔드 오픈소스 플랫폼이다. 도구, 라이브러리, 커뮤니티 리소스로 구성된 포괄적이고 유연한 생태계를 통해 연구원들은 ML에서 첨단 기술을 구현할 수 있고 개발자들은 ML이 접목된 애플리케이션을 손쉽게 빌드 및 배포할 수 있다. (출처: tensorflow 홈페이지)
한마디로 파이썬 같은 건데, 머신러닝 돌릴 때 굉장히 간단한 코드로 모든 것을 할 수 있다.
Tensorflow 자체는 코드가 조금 어려웠으나, 그 위에 Keras라는 API를 얹어 코드가 매우 간단해졌다.
이번 포스팅에서는 Tensorflow 홈페이지 튜토리얼에서 제공하는 Keras가 적용된 Basic classification을 작성해보았다.
0-1. Tensorflow with Keras
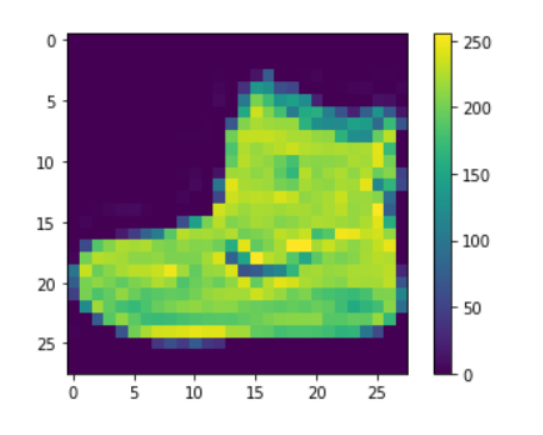
이 튜토리얼에서는 운동화나 셔츠 같은 옷 이미지를 분류하는 신경망 모델을 train한다.
완전한 텐서플로(TensorFlow) 프로그램을 빠르게 살펴 보고, 자세한 내용은 앞으로 배우면서 더 설명한다. 텐서플로 모델을 만들고 훈련(train)할 수 있는 고수준 API인 tf.keras를 사용한다.
from __future__ import absolute_import, division, print_function, unicode_literals, unicode_literals
# tensorflow와 tf.keras를 임포트합니다
import tensorflow as tf from tensorflow import keras
# 헬퍼(helper) 라이브러리를 임포트합니다
import numpy as np import matplotlib.pyplot as plt # tensorflow version print(tf.__version__)
1. 패션 MNIST 데이터셋 임포트하기
10개의 범주(category)와 70,000개의 흑백 이미지로 구성된 패션 MNIST 데이터셋을 사용한다. 이미지는 해상도(28x28 픽셀)가 낮은 개별 옷 품목을 나타낸다:
- 패션 MNIST
컴퓨터 비전 분야의 "Hello, World" 프로그램격인 고전 MNIST 데이터셋을 대신해서 자주 사용된다. MNIST 데이터셋은 손글씨 숫자(0, 1, 2 등)의 이미지로 이루어져 있으며, 여기서 사용하려는 옷 이미지와 동일한 포맷이다.
패션 MNIST는 일반적인 MNIST 보다 조금 더 어려운 문제이고 다양한 예제를 만들기 위해 선택했다. 두 데이터셋은 비교적 작기 때문에 알고리즘의 작동 여부를 확인하기 위해 사용되곤 한다. 코드를 테스트하고 디버깅하는 용도로 좋다.
네트워크를 훈련하는데 60,000개의 이미지를 사용한다. 그다음 네트워크가 얼마나 정확하게 이미지를 분류하는지 10,000개의 이미지로 평가하겠다. 패션 MNIST 데이터셋은 텐서플로에서 바로 임포트하여 적재할 수 있다:
- train_images, train_labels 배열: 모델 학습에 사용되는 train set.
- test_images, test_labels 배열: 모델 테스트에 사용되는 test set.
이미지는 28x28 크기의 넘파이 배열이고 픽셀 값은 0과 255 사이.
레이블(label)은 0에서 9까지의 정수 배열이며, 이 값은 이미지에 있는 옷의 클래스(class)를 나타낸다:
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515[=================================]-0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880[==============================]-1s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148[===============================================]-0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102[==============================]-0s 0us/step
Label Class
0T-shirt/top
1 Trouser
2 Pullover
3 Dress
4 Coat
5 Sandal
6 Shirt
7 Sneaker
8 Bag
9 Ankle boot
각 이미지는 하나의 레이블에 매핑되어 있다. dataset에 클래스 이름이 들어있지 않기 때문에 나중에 이미지를 출력할 때 사용하기 위해 별도의 변수를 만들어 저장한다:
model = keras.Sequential([ keras.layers.Flatten(input_shape=(28,28)), keras.layers.Dense(128, activation='relu'), keras.layers.Dense(10, activation='softmax')])
tf.keras.layers.Flatten: 네트워크의 1st layer로 2차원 배열(28 x 28 픽셀)의 이미지 포맷을 28 * 28 = 784 픽셀의 1차원 배열로 변환한다. 이 층은 이미지에 있는 픽셀의 행을 펼쳐서 일렬로 늘린다. 이 층에는 학습되는 가중치가 없고 데이터를 변환하기만 한다.
tf.keras.layers.Dense: 픽셀을 펼친 후에는 두 개의 층이 연속되어 연결된다. 이 층을 밀집 연결(densely-connected) 또는 완전 연결(fully-connected) 층이라고 부른다.
- 첫 번째 Dense layer: 128개의 노드(또는 뉴런)를 가지며, 두 번째 (마지막) layer는 10개 노드의 소프트맥스(softmax) 층이다. 이 layer은 10개의 확률을 반환하고 반환된 값의 전체 합은 1이다. 각 노드는 현재 이미지가 10개 클래스 중 하나에 속할 확률을 출력한다.
5. 모델 컴파일(Compile the model)
모델을 훈련하기 전에 필요한 몇 가지 설정이 모델 컴파일 단계에서 추가된다:
- 손실 함수(Loss function): 훈련 하는 동안 모델의 오차 측정. 모델의 학습이 올바른 방향으로 향하도록 이 함수를 최소화해야 한다.
- 옵티마이저(Optimizer): 데이터와 손실 함수를 바탕으로 모델의 업데이트 방법을 결정.
- 지표(Metrics): 훈련 단계와 테스트 단계를 모니터링하기 위해 사용한다. 다음 예에서는 올바르게 분류된 이미지의 비율인 정확도를 사용합니다.