
K8s에는 각 컴포넌트마다 다른 버전을 가지고 있다.
그런데, kube-apiserver가 가장 상위 버전이고, 다른 것들은 kube-apiserver보다 높은 버전을 가질 수 없다. (동일은 가능)
단, kubectl의 경우 상위버전, 동일버전, 하위버전 모두 가질 수 있다.
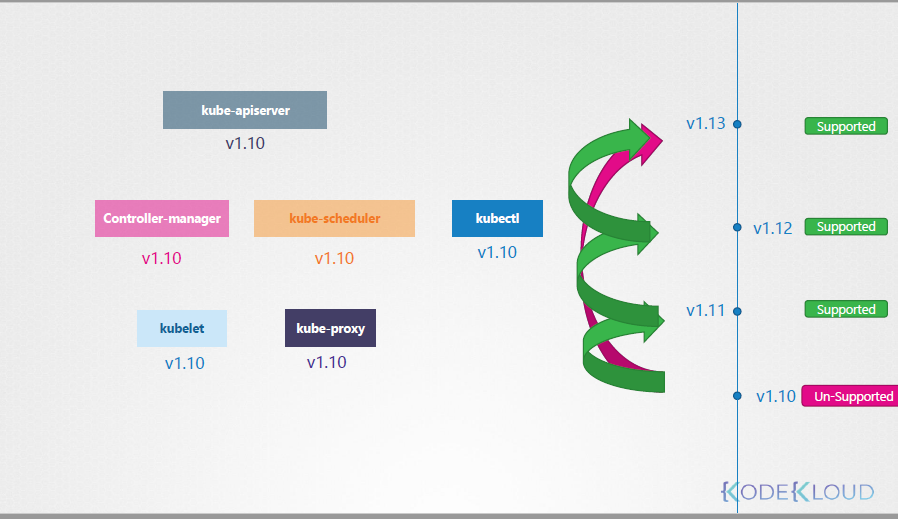
그리고, k8s는 하위 3개의 minor버전까지만 support하기 때문에, v1.13이 배포되었다는 기준으로
v.11까지만 upgrade할 수 있다.
그리고, upgrade를 할 땐 v1.10 -> v1.13으로 바로 가지말고, minor버전을 하나씩 올리라고 권고하고 있다.
ex. v1.10 -> v1.11 -> v1.12 -> v1.13

그럼, upgrade는 어떻게 진행할까?
GCP등 ServiceProvider에 올린 경우 버튼 몇번으로 진행할 수 있고,
이 외는 kubeadm을 통해 진행할 수 있다.

upgrade 절차는 Master Node를 먼저 진행하고, 그 이후엔 3가지 전략이 있다.
1) 전체Node 삭제 후 전체 Node 생성: service impacted
2) 하나의 Node씩 Upgrade: Impact 없음

3) 최신 버전인 new Node를 하나 생성한 후, 기존 node를 하나씩 upgrade하고, 기존 node중 하나 삭제
(3은 cloud 환경에 있다면 가장 쉽고 편한 방법)

실제 upgrade command는
1. kubeadm upgrade plan을 통해 available한 pkg version을 조회한다.
# kubeadm upgrade plan

1 apt-get을 통해 pkg를 땡겨오고 (available한 건 v1.13.4였지만, 버전이 v1.11.3이었으므로 하나씩 올린다)
2. kubeadm upgrade apply v1.12.0을 통해 pkg를 upgrade한다.
3. version을 조회하면 아직 v1.11.3이다.
4. 이유는, 해당 버전은 kubelet을 기준으로 보이는데, kubelet이 upgrade되지 않았기 때문이다.
그래서 kubelet을 마지막으로 upgrade한다.
# apt get upgrade -y kubeadm=1.12.0-00
# kubeadm upgrade apply v1.12.0
# kubectl get nodes
# apt-get upgrade -y kubelet=1.12.0-00
# systemctl restart kubelet

각 Node들을 upgrade할 땐, 이전 포스팅에서 다루었던 drain, uncordon 명령을 통해
https://countrymouse.tistory.com/entry/cka-6-1
node에 있는 pod가 미리 다른 pod로 옮겨갈 수 있게 설정해준다.
출처: Udemy 사이트의 Certified Kubernetes Administrator (CKA) with Practice Tests 강의






















































